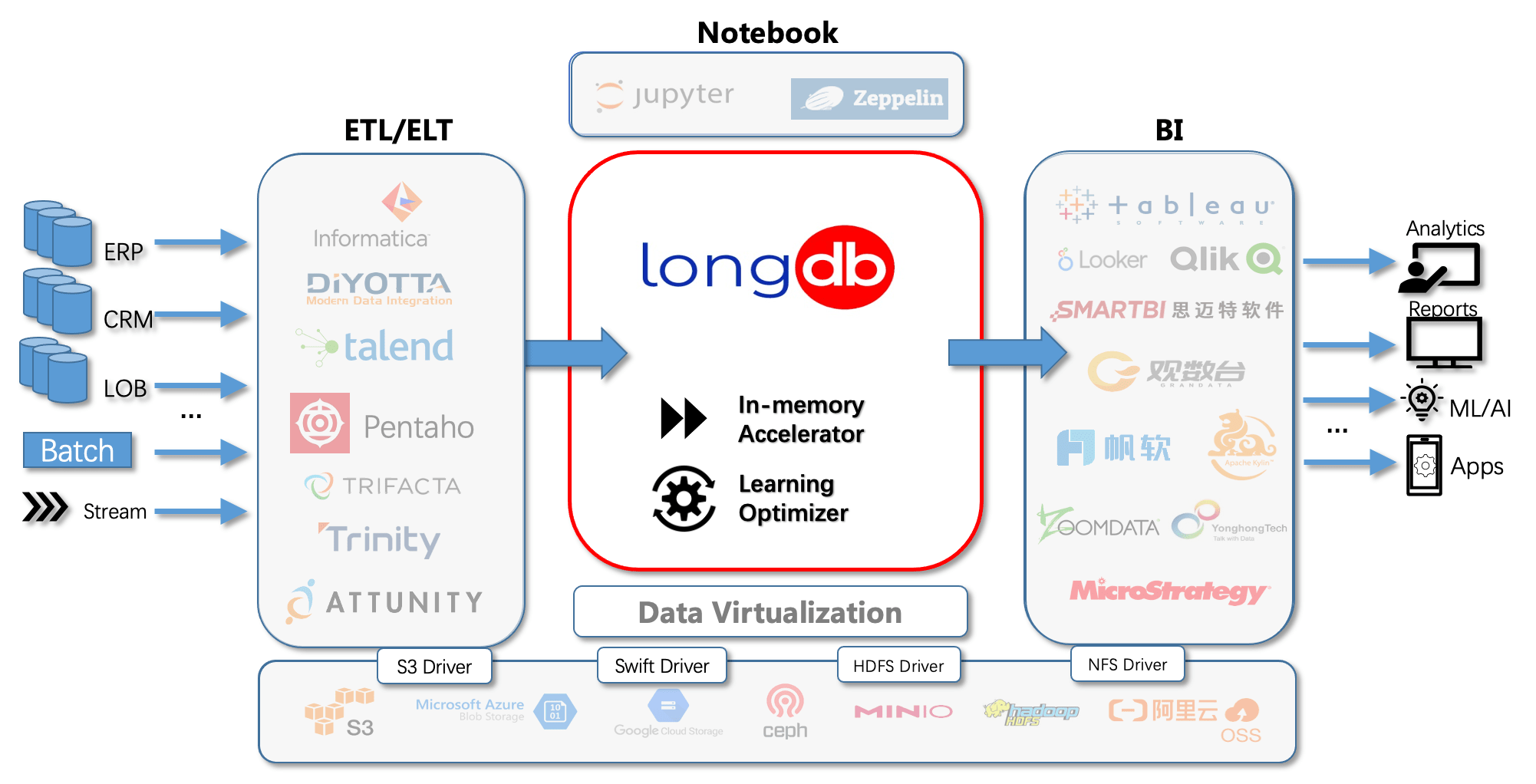
简单可扩展的流批一体架构
LongDB实现了Lambda架构的功能,但避免了Lambda架构的复杂性以及数据的冗余,在同一个平台同时支持流式和批量数据处理。用户还可以选择使用流行编程语言或BI工具通过标准接口连接LongDB,或者通过与Spark的专用接口无缝集成方式访问LongDB。
LongDB可以从几个节点动态扩展到数千个节点,以支持各种规模的应用程序。
经济高效的混合引擎
LongDB的核心是实现分布式存储和计算的双模关系型数据库(分布式事务处理和并行分析合二为一)。与内存数据库不同,LongDB不会强制企业将所有数据都放在内存中,因为随着数据量的增长,这些数据存储成本会变得非常昂贵。LongDB会利用数据的冷热特点选择最佳存储配置并同时利用内存计算来加速数据处理速度。
当你在 LongDB 执行SQL时,它会根据集群上的数据分布并使用先进的基于成本的优化器来确定通过基表或索引对数据的最佳的访问方式、最佳的关联排序、高效的并行执行路径,以及特有的根据查询特性和数据来选择执行查询的最佳计算引擎(事务或分析)。
高性能分布式计算架构
LongDB拥有高性能的分布式计算架构,通过将计算推送到每个分布式数据分片,进行大规模并行化的谓词关联、聚合和函数运算。LongDB 数据库为不同的数据处理任务提供作业调度和资源隔离。充分利用分布式并行处理提高系统资源利用率并使得事务和分析作业均衡。
高度融合的系统
LongDB平台支持标准协议(如ANSI SQL, JDBC, REST)以确保客户现有的工具可以无缝连通而不用专门重写已有的工具和应用程序。我们还提供了实用的数据和应用迁移工具,使用户作业的迁移尽量减少成本。如果客户已有使用大数据平台工具和组件,LongDB可以平滑对接以及共存。