Delivering Unmatched Database Capabilities using Hadoop Ecosystem Components
Modern Hadoop ecosystem has grown beyond the original quartet: HDFS, Yarn, MapReduce, and Hadoop Common. With Hbase and Spark introduced into the ecosystem, we can utilize them and build higher level systems to combine Hbase's high read/write throughput and Spark's unique capability for parallel execution of complex/analytical workloads. A lot is under the hood to make the whole system perform as a HTAP engine, supporting ANSI-SQL and full-functionality of a relational database with ACID properties. It's an HTAP platform without the need to move underlying data between TP and AP modules. Customers no longer need to suffer the platform choice between favoring transactional (CRUD operations on data) or analytical (typically append-only data stores) workloads. We can also leverage the proven robustness and linear scalability of the Hadoop ecosystem.
< 2ms
Single record retrieval time on a database with multi-PB in size
< 20ms
Single record update at PB scale
< 100ms
A tactical query with 40-table joins
120s
An OLAP query joing 150 tables
440
Capable of parsing and executing a query with 440-table joins
100MB
Batch data loading speed per node per second
You do not need to purchase costly proprietary appliances while enjoying the speed of a commercial database. You can have a general-purpose HTAP database on commodity hardware or virtual machines on public cloud. If you find it difficult to utilize the value from existing Hadoop platforms, we can certainly help you do more in your existing big data environment.
Advanced Cost-Based Optimizer

Key members of the LongDB founding team had years of experience building industry-leading optimizers for MPP databases. The optimizer will automatically choose the right execution engine and strategy to process TP or AP workloads, based on automatically collected data demographics information. The decision is done automatically without human intervention. In the meantime, users have the visibility of the magic through query plans and live execution graphs. We also provide a set of tools to impact/tune the execution in certain cases (e.g., when statistics information is stale). If your data growth or workloads follow certain patterns, the optimizer will learn and adopt the right execution strategies. The self-optimizing capability will be a key differentiation.
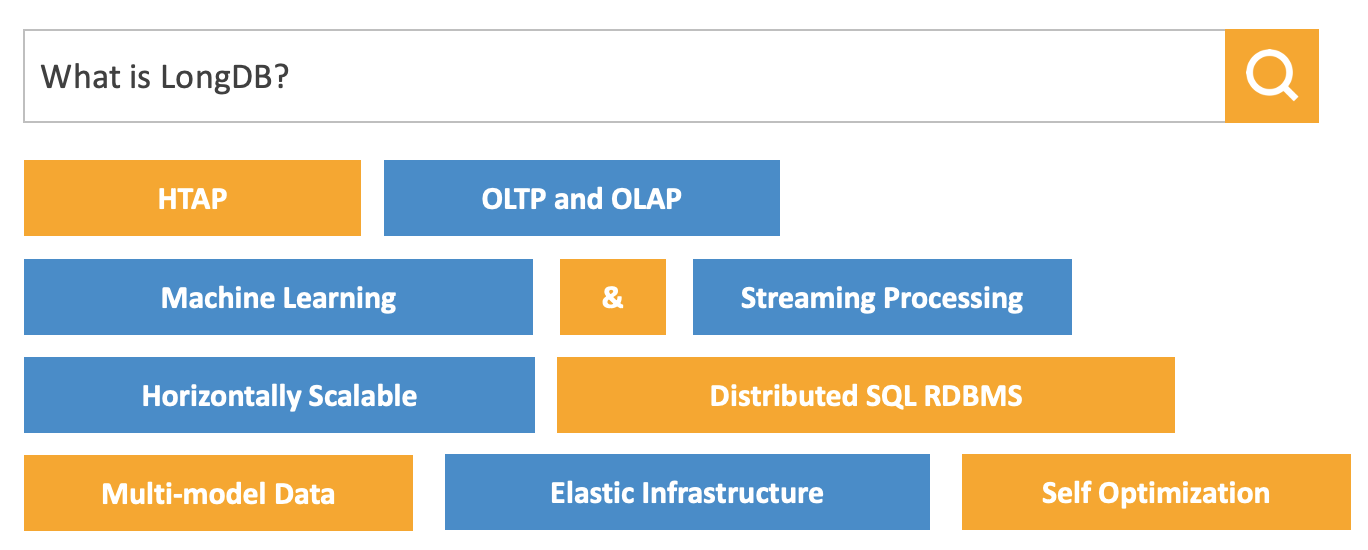
Important Features of the Product
With the hybrid architecture, LongDB possesses unique capabilities, which will strongly support enterprises' data-driven infrastructure needs, enpowering enterprises to gain real-time insights and make timely business decisions. This is a great competitive advantage in today's fast-changing business world.
LongDB platform is an enterprise level data platform. It has an easy-to-use GUI management interface and is easy to be deployed to various environments (on-prem, private cloud and public cloud). We also provide a set of tools for development and operations teams.
LongDB's query language is ANSI SQL-2003 compliant. It also has additional improvements that make the query language highly compatible with mainstream commercial database dialects like DB2, Teradata, and Oracle.
LongDB has deep integration with Apache Spark for analytical workload execution. Spark has a highly efficient in-memory processing mechanism that LongDB leverages. When data grows beyond memory boundary, it can spill to secondary storage (e.g., SSD/HDD).
More importantly, LongDB's analytical processing capability is not limited to Spark's ability. With the full knowledge of data demographics and advanced cost-based mechanisms, the LongDB optimizer can generate more optimized query plans than Spark can. It can utilize the multiple storage layers to make the best decision based on the temparature of the data (hot, warm, cold).
LongDB leverages mature Hadoop ecosystem to set up distributed service architecture. One key component is Apache HBase. In companies like Facebook and Alibaba, HBase technology has been proven to be able to scale to thousands of nodes using commodity hardware on servers. The ecosystem is still evolving, which we can continue to leverage.
LongDB is a flexible and versatile data platform. It supports both OLTP and OLAP, among AI/ML workloads on the same infrasturcture. With the underlying open source ecosystem components, it goes beyond the power of traditional relational database. It is an evolving environment that supports different types of data and workloads to unlock the true power of enterprise data.